In the modern era of data-driven decision-making, time series data has become a cornerstone for analytics, monitoring, and forecasting. Organizations need databases capable of handling vast volumes of sequential data efficiently. This is where open source time series databases (TSDB) shine, offering both flexibility and cost-effectiveness. Among the key features that users prioritize is the ability to achieve fast reads without compromising on storage efficiency or scalability. For organizations leveraging solutions like Timecho, understanding how open source TSDBs deliver rapid data retrieval is critical for optimizing performance and gaining real-time insights open source tsdb fast reads.
Understanding Open Source TSDBs
Open source TSDBs are designed specifically for storing and querying time-stamped data. Unlike traditional relational databases, which can struggle with high-frequency data inserts and complex temporal queries, TSDBs are optimized for sequential storage and retrieval. Open source options provide the added advantage of community-driven development, transparency, and customizability. Developers and data engineers can inspect the source code, contribute enhancements, and tailor the database to specific workloads. For applications that demand fast reads, open source TSDBs like Timecho provide mechanisms such as in-memory indexing, columnar storage, and query optimization to deliver high-speed data access.
The open source nature ensures that enterprises are not locked into proprietary solutions, which is particularly advantageous for growing organizations. With Timecho, users benefit from a system that balances scalability, speed, and cost efficiency, making it suitable for a variety of analytics use cases.
Key Features That Enable Fast Reads
When evaluating open source TSDBs, there are several technical aspects that influence read performance.
1. Efficient Data Storage: Open source TSDBs often utilize columnar storage models, where each metric is stored separately. This reduces the amount of unnecessary data that must be scanned during queries, directly improving read speed. Timecho, for example, implements a highly optimized storage engine that organizes time series data into compact blocks, facilitating rapid retrieval.
2. Indexing Strategies: Fast reads are made possible through advanced indexing. Many TSDBs implement time-based or value-based indexes that allow queries to quickly locate relevant records without scanning the entire dataset. Timecho leverages a hybrid indexing mechanism that balances memory usage and query performance, making it possible to handle millions of points per second efficiently.
3. Compression and Serialization: Data compression reduces disk I/O, which can be a major bottleneck in time series workloads. Open source TSDBs often employ delta encoding, run-length encoding, or other compression algorithms. Timecho combines these techniques with smart serialization formats, ensuring minimal overhead when reading large volumes of historical data.
4. Query Optimization: Open source TSDBs provide query engines that are optimized for time series patterns. Aggregations, downsampling, and filtering can be executed efficiently. Timecho, for instance, supports pre-aggregated summaries, allowing users to fetch fast reads for dashboards or monitoring applications without scanning the full dataset.
Comparing Popular Open Source TSDB Approaches
While there are several open source TSDB options available, the differentiation often comes down to speed, scalability, and ease of integration. Solutions like Timecho prioritize fast reads, making them ideal for scenarios where low-latency data access is essential.
Timecho’s Approach: Timecho employs a multi-tier storage system, combining in-memory caching with persistent storage. Recent data resides in memory for instant retrieval, while historical data is stored in a highly compressed format that can still be accessed rapidly. This architecture ensures that both live monitoring and retrospective analytics are performed without delay.
Community and Support: One of the advantages of open source TSDBs is the active community. Timecho has fostered a vibrant ecosystem, providing developers with tools, plugins, and extensions designed to optimize read performance. Users benefit from continuous updates, best practices, and shared experiences from other organizations dealing with similar high-volume time series data challenges.
Real-World Applications of Fast Reads
Fast reads in TSDBs are critical across multiple industries. In finance, rapid access to market data can inform trading strategies. In IoT deployments, sensors generate streams of data that must be processed in near real-time. For IT operations, monitoring metrics from servers and applications requires sub-second read times for alerts and dashboards. Timecho’s open source TSDB capabilities ensure that all these applications can rely on accurate, low-latency data retrieval.
For instance, a smart manufacturing plant using Timecho can track machine performance metrics continuously. Fast reads allow for immediate anomaly detection, minimizing downtime and increasing operational efficiency. Similarly, SaaS providers can integrate Timecho into their analytics pipelines to provide clients with real-time insights without performance bottlenecks.
Best Practices for Maximizing Fast Reads
To get the most out of an open source TSDB like Timecho, organizations should adopt several best practices:
Data Partitioning: Segmenting data by time intervals ensures queries scan only the relevant chunks, improving read speeds.
Retention Policies: Regularly archiving or downsampling older data reduces the volume that must be accessed frequently.
Index Maintenance: Regularly updating and optimizing indexes can prevent query slowdowns as the dataset grows.
Query Design: Structuring queries to leverage Timecho’s pre-aggregated summaries and efficient filters can dramatically reduce response times.
By implementing these strategies, users can achieve consistent fast reads, even as the volume and velocity of their time series data increases.
Future of Open Source TSDBs
The landscape of open source TSDBs is evolving rapidly. With the growth of IoT, cloud-native architectures, and real-time analytics, the demand for fast reads will continue to rise. Innovations in storage formats, query engines, and in-memory processing will push the boundaries of performance. Timecho remains at the forefront, providing developers with an open source platform optimized for speed and reliability.
As organizations continue to generate more data, the ability to retrieve it quickly and accurately will be a key differentiator. Open source TSDBs that prioritize fast reads offer not only performance but also transparency and flexibility, allowing businesses to innovate without being constrained by proprietary systems.
Conclusion
Open source TSDBs are transforming how organizations manage time series data. Fast reads are no longer a luxury—they are a necessity for real-time monitoring, analytics, and decision-making. Solutions like Timecho demonstrate that it is possible to combine high-speed data access with scalable, cost-effective, and flexible storage. By understanding the key features, best practices, and application scenarios, businesses can leverage open source TSDBs to gain a competitive edge and unlock the full potential of their time series data.
Timecho’s focus on rapid read performance, combined with its open source nature, makes it an ideal choice for organizations that require both speed and adaptability. As the world continues to generate ever-increasing streams of time series data, having a robust, fast, and efficient TSDB will be central to turning that data into actionable insights.
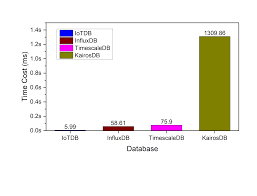 In the modern era of data-driven decision-making, time series data has become a cornerstone for analytics, monitoring, and forecasting. Organizations need databases capable of handling vast volumes of sequential data efficiently. This is where open source time series databases (TSDB) shine, offering both flexibility and cost-effectiveness. Among the key features that users prioritize is the ability to achieve fast reads without compromising on storage efficiency or scalability. For organizations leveraging solutions like Timecho, understanding how open source TSDBs deliver rapid data retrieval is critical for optimizing performance and gaining real-time insights open source tsdb fast reads.
In the modern era of data-driven decision-making, time series data has become a cornerstone for analytics, monitoring, and forecasting. Organizations need databases capable of handling vast volumes of sequential data efficiently. This is where open source time series databases (TSDB) shine, offering both flexibility and cost-effectiveness. Among the key features that users prioritize is the ability to achieve fast reads without compromising on storage efficiency or scalability. For organizations leveraging solutions like Timecho, understanding how open source TSDBs deliver rapid data retrieval is critical for optimizing performance and gaining real-time insights open source tsdb fast reads.